.png)
This article is a synthesis of a recent Deloitte paper on the future of pharma R&D labs. I summarize the key points of the publication and add new insights to support C-level executives and companies in effectively embracing digital transformation.
I also share my personal perspective on digital transformation, as detailed in the DLM White Paper that I recently published to help organizations turn their data into tangible business value. Although this white paper focuses primarily on Contract Research Organizations (CROs), it highlights several principles and insights that strongly resonate with the findings discussed in the Deloitte report.
Finally, I draw connections between this analysis and recent observations made at the BioTechX Congress, where I had the opportunity to engage with multiple pharma leaders and stakeholders shaping the future of data-driven R&D.
I would like to thank Shahin Gharakhanian, MD, for sharing this insightful Deloitte paper with me.
📄 Deloitte publication: Read the paper here.
Introduction & Key Takeaways
Pharma R&D is at a turning point. Deloitte highlights that modernizing laboratories is not just about technology adoption — it is about creating a sustainable innovation engine. Moving from siloed, manual systems to predictive, automated labs can dramatically accelerate drug discovery and development.
Key takeaways:
- Digital maturity in R&D follows six steps by Deloitte: non-digital → nascent digital → siloed data → connected → automated → predictive.
- Connectivity and harmonization of data are prerequisites for automation.
- Prediction is not the endgame: mastering digital transformation requires creating business value from data.
- Organizations must move beyond “tool aggregation” and adopt a business-driven vision of digitalization.
- The “research data product” concept is central: transforming raw data into curated, reusable assets that fuel innovation and growth.
From Siloed Systems to Predictive R&D Labs
Deloitte’s framework describes six maturity stages for R&D digital transformation: non-digital → nascent digital → data silos → connected → automated → predictive. Most organizations today remain stuck in the middle—managing disconnected instruments and fragmented data streams that limit automation and insight generation.
The report emphasizes that automation requires connecting processes and instruments, but provides little guidance on how to achieve this. This is where the DLM White Paper — which I recently published to help companies succeed in their digital transformation — offers a complementary perspective: true connection requires harmonization through annotation.
In my opinion, automation should not be viewed as a purely technical goal. Prediction, even when powered by AI or digital twins, is only meaningful if it creates measurable business value. Organizations can predict outcomes accurately, but if those insights do not translate into new products, services, or improved client value, then digital transformation is still incomplete.
👉 According to the DLM Quadrant, real digital mastery happens when data becomes an active business asset — powering new data-driven services (DLM White Paper).
Data Harmonization: The True Prerequisite for Automation
From my point of view, data harmonization is the key bottleneck preventing process automation. This observation was confirmed during the BioTechX Congress, where major pharmaceutical companies described how they address this challenge.
For example, Roche shared its approach of building an internal metadata registry — an enterprise ontology system — to annotate data and make every process “speak the same language.” While this approach is powerful, it is long, costly, and complex to maintain, which makes it unattainable for many organizations.
Although ontological frameworks may look elegant in theory, I believe they are not always the most appropriate solution for practical data harmonization. Ontologies require deep hierarchical structuring of terms, which often exceeds the immediate needs and capacities of most companies.
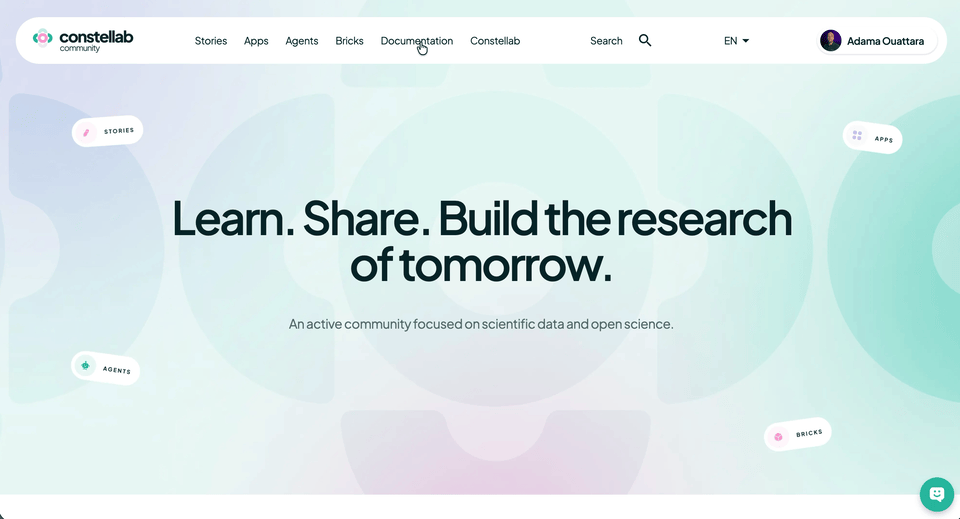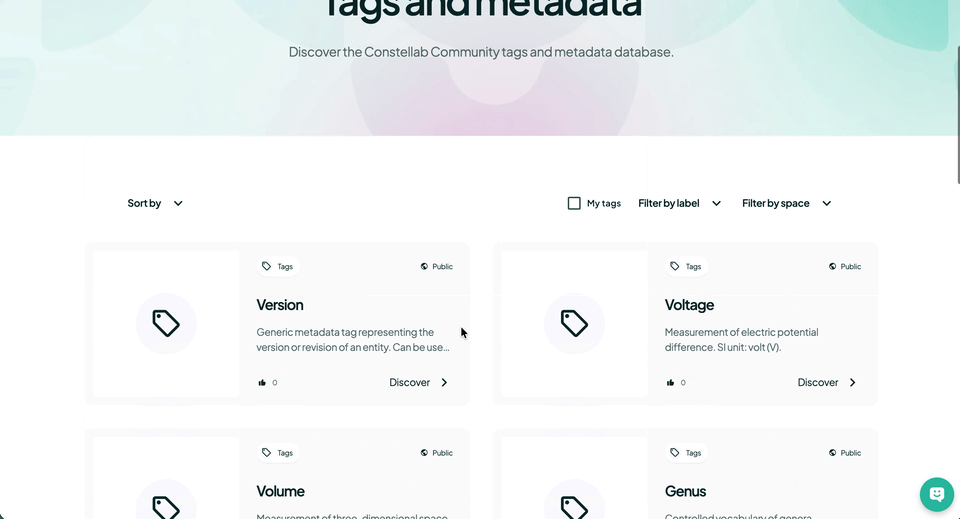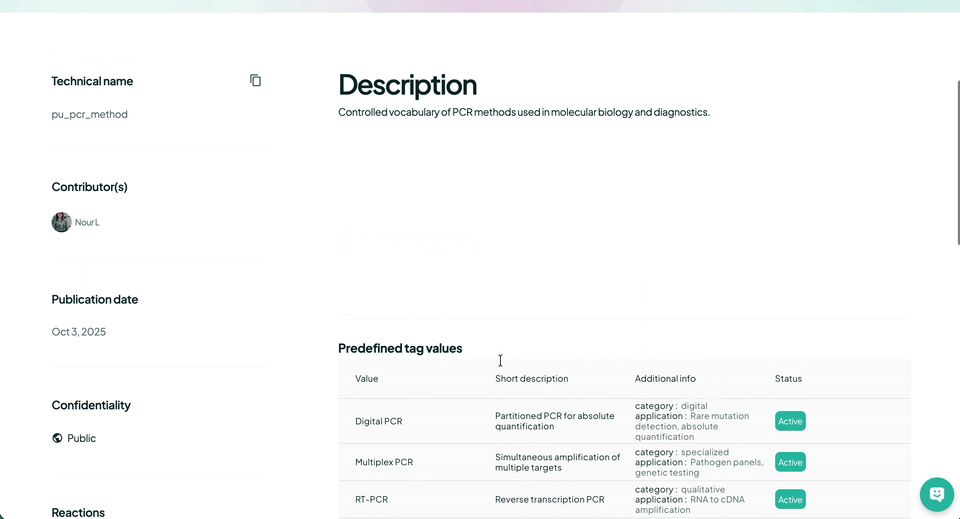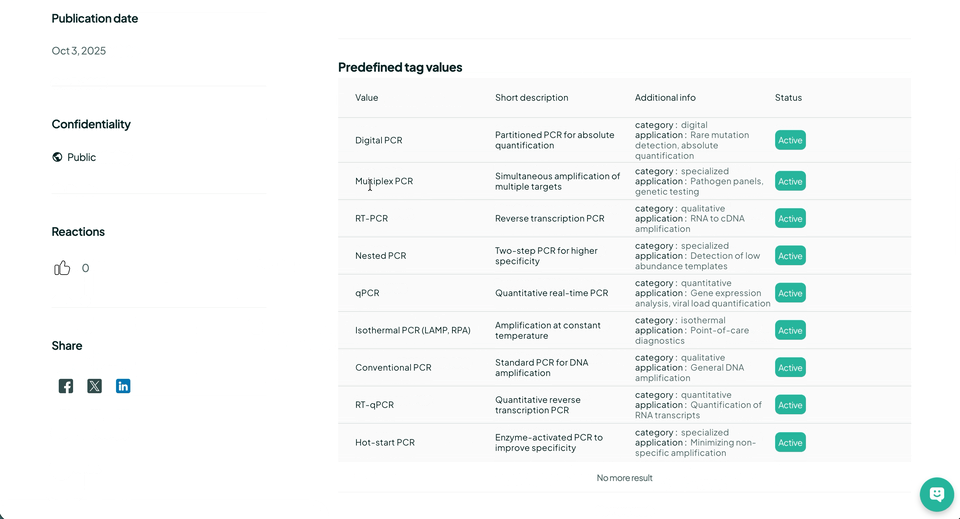
At Gencovery, we recommend a one-level annotation approach — simple, unified, and interoperable — to harmonize enterprise processes and data. Rather than building in-house registries that are difficult to connect with external systems, we encourage organizations to leverage open-source compendiums. This is the philosophy behind the Constellab Community tagging system (https://constellab.community/tags), which promotes lightweight, shared annotation for scientific and operational data.
👉 Unlike traditional data structuring — which is expensive, rigid, and often freezes processes — annotation is flexible, cost-effective, and scalable. Many organizations mistakenly view structuring as the default route to digitalization, yet annotation-based harmonization offers a far faster and more sustainable path to automation.
The Rise of Generative AI for Data Harmonization
Some organizations have recently begun exploring Generative AI (GenAI) to automate data harmonization internally. While this trend is promising, it does not fully solve the core challenge of interoperability — especially when multiple registries or systems need to connect across different organizations.
GenAI can indeed accelerate internal data processes, but it requires highly specialized expertise to implement, qualify, and maintain — particularly in regulated environments such as healthcare and life sciences. Ensuring compliance, traceability, and reproducibility under such complex AI-driven architectures is a major challenge for most companies.
To address this, Gencovery has chosen to promote a collaborative approach that combines the power of GenAI with openness and interoperability. With Constellab, each organization can deploy its own GenAI agents while benefiting from a shared, open metadata registry — allowing every process to “speak the same language.”
This model enables organizations to leverage GenAI more effectively, unifying terminology both within and across enterprises. Moreover, Constellab’s tools are designed to be easily customizable and qualified without requiring advanced IT or data engineering skills — making R&D automation and digital transformation accessible to everyone.
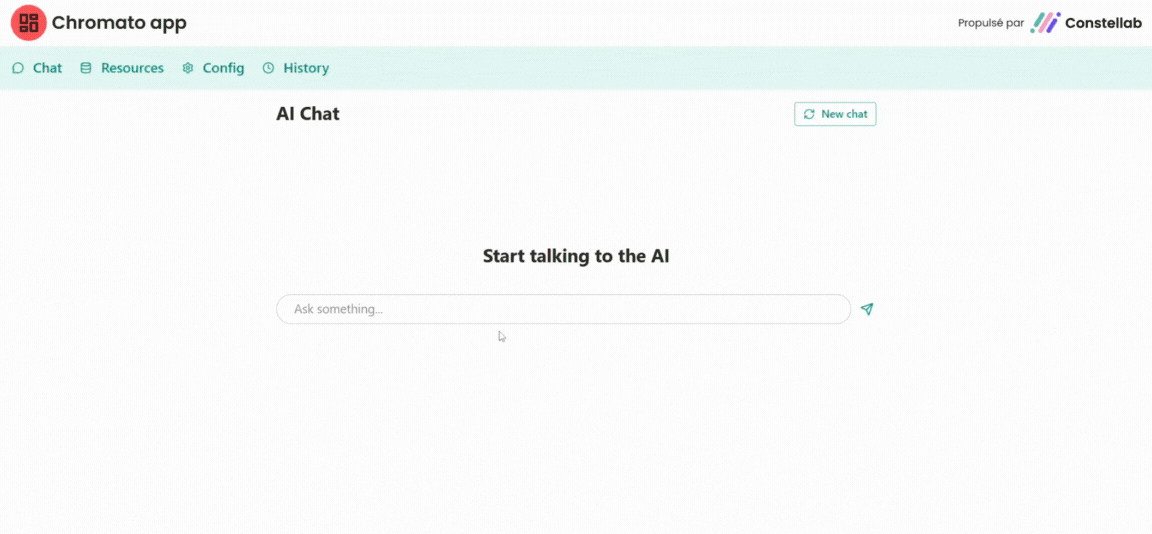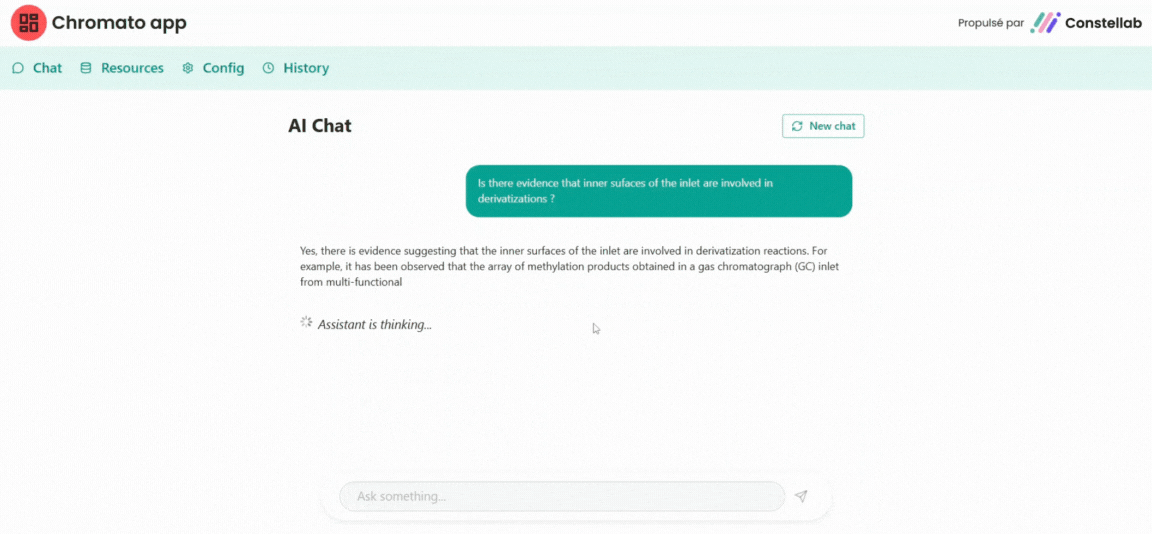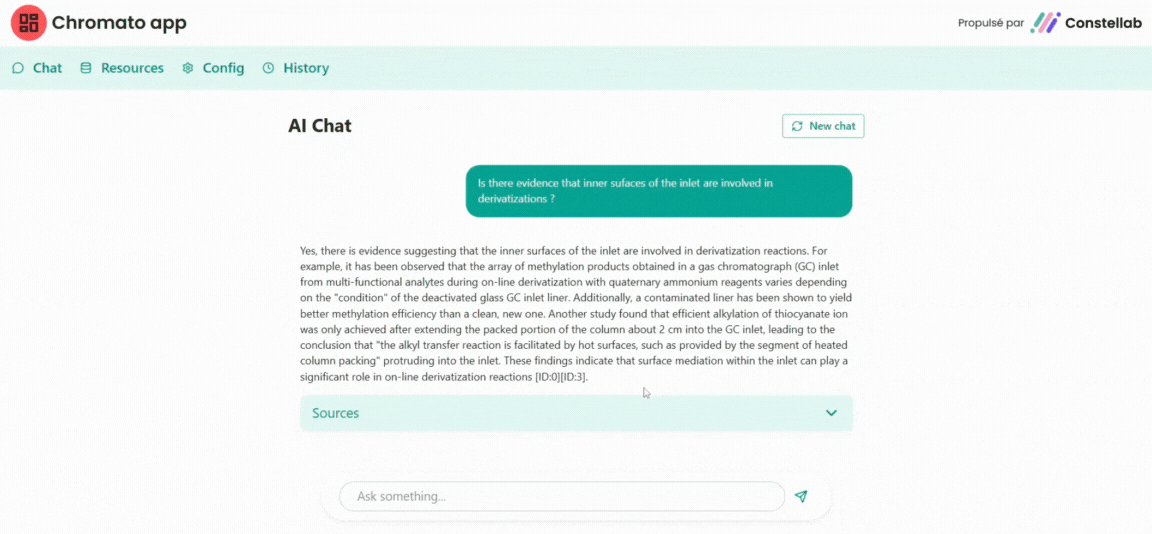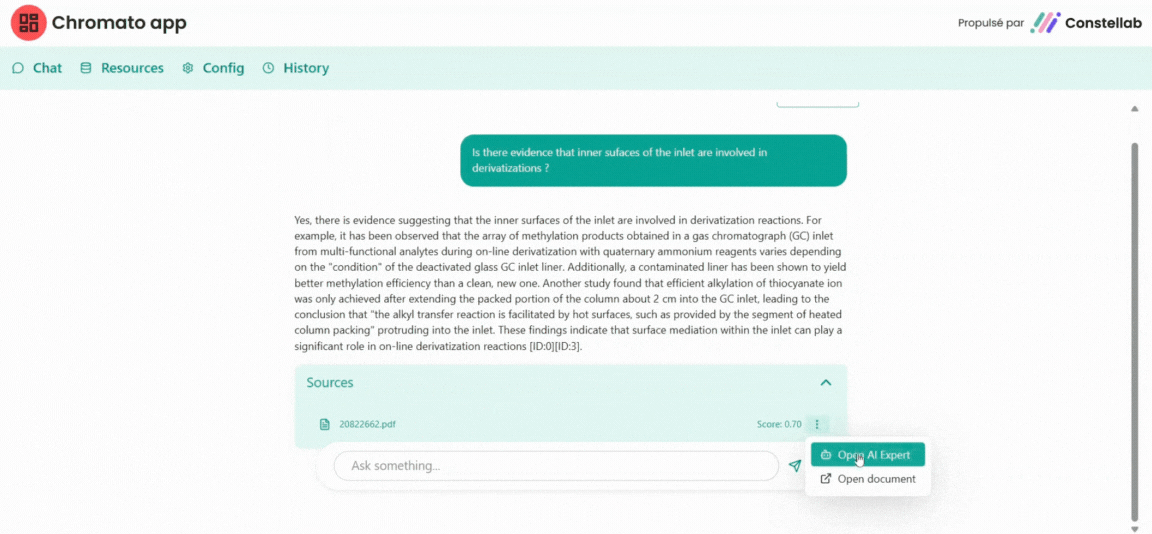
See the application here : https://constellab.community/apps/76a51a59-58c5-494f-8ea9-775ca60ccfb5/chromato-ai
This RAG engine can be configured with any laboratory data and seamlessly connected to metadata layers and advanced analytical tools — including statistics, machine learning, and digital twins — to help transform your operations into truly predictive R&D labs.
Beyond Prediction: Toward Data Mastery
The predictive step—where AI, digital twins, and integrated wet/dry labs generate insights—marks real progress. However, in my view, prediction alone does not guarantee business value.
An organization may predict outcomes effectively, but if those insights do not translate into measurable products, services, or client value, the digital transformation is still incomplete.
👉 This is where I connect with the DLM Quadrant, described in the DLM White Paper: True digital mastery occurs when data is not only predictive but also activated as a business asset—fueling new services, SaaS modules, APIs, or client-facing platforms.
I would even go further and argue that there is an additional stage beyond prediction: “Data Services.” Some organizations achieve strong value simply by producing, cleaning, and delivering data to clients—without necessarily deploying AI or digital twins. Misunderstanding this distinction leads many companies to over-invest in unnecessary complexity.

Maximizing the Impact of “Lab of the Future” Initiatives
Simply aggregating digital tools is not enough. Deloitte stresses the need for integration, but the DLM perspective goes further: success requires a clear business vision driving digitalization. Without alignment between leadership, R&D, and finance, digital initiatives risk becoming cost centers rather than growth engines.
Enhancing R&D Data Utility Through “Research Data Product” focus
Deloitte introduces the concept of “research data products”—well-annotated, reusable, and governed datasets. This resonates strongly with the DLM virtuous cycle of growth (DLM White Paper):
- Clients feed data into the system.
- Data is curated and activated.
- Businesses deliver improved services, which in turn generate more data.
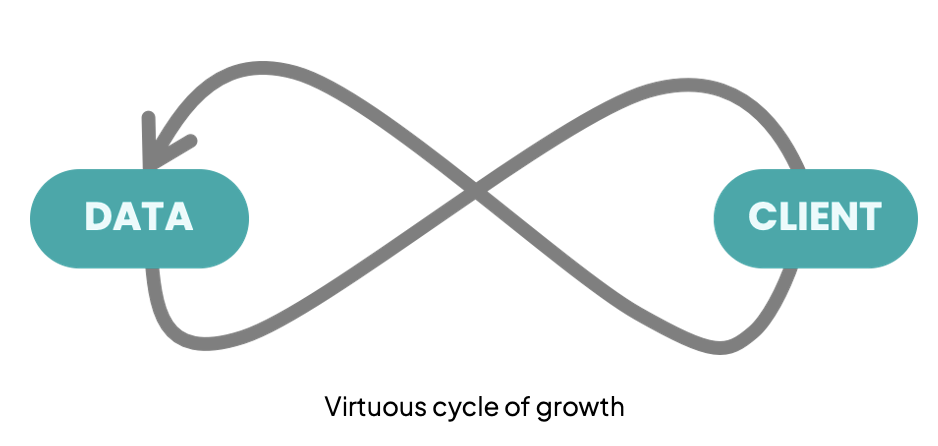
👉 The bottom line: data is no longer a byproduct of R&D—it is itself a product. Digitalization should systematically treat data as a core offering, creating both scientific and economic value.
Conclusion
Future-proofing pharma R&D labs requires more than digital tools—it demands a shift in mindset.
- From structuring to annotating and harmonizing.
- From prediction to business activation.
- From tools to data services and products.
Organizations that embrace this vision will not only accelerate discovery but also unlock sustainable revenue streams, making their R&D truly future-ready.
Contact me
- Adama Ouattara, Cofounder and CEO of Gencovery
- LinkedIn: https://www.linkedin.com/in/adama-ouattara-689b2b49/
- E-mail: douattara@gencovery.com

Comments (0)
Write a comment