Introduction
We present here a use case on the analysis of the Iris dataset using K-Means clustering method, using the Gaia brick of our platform Constellab. The Iris dataset consists of 50 samples from each of three species of Iris flower (Iris setosa, Iris virginica and Iris versicolor). Four feature were measured from each sample: the length and the width of the sepals and petals, in centimeters. The K-Means algorithm clusters data by trying to separate samples in groups of equal variance, minimizing a specific criterion.
Protocol steps
STEP 1 Data preparation and preview
We start by loading the iris dataset from our computer in the Databox. One can have a preview of the dataset by clicking on the imported file.
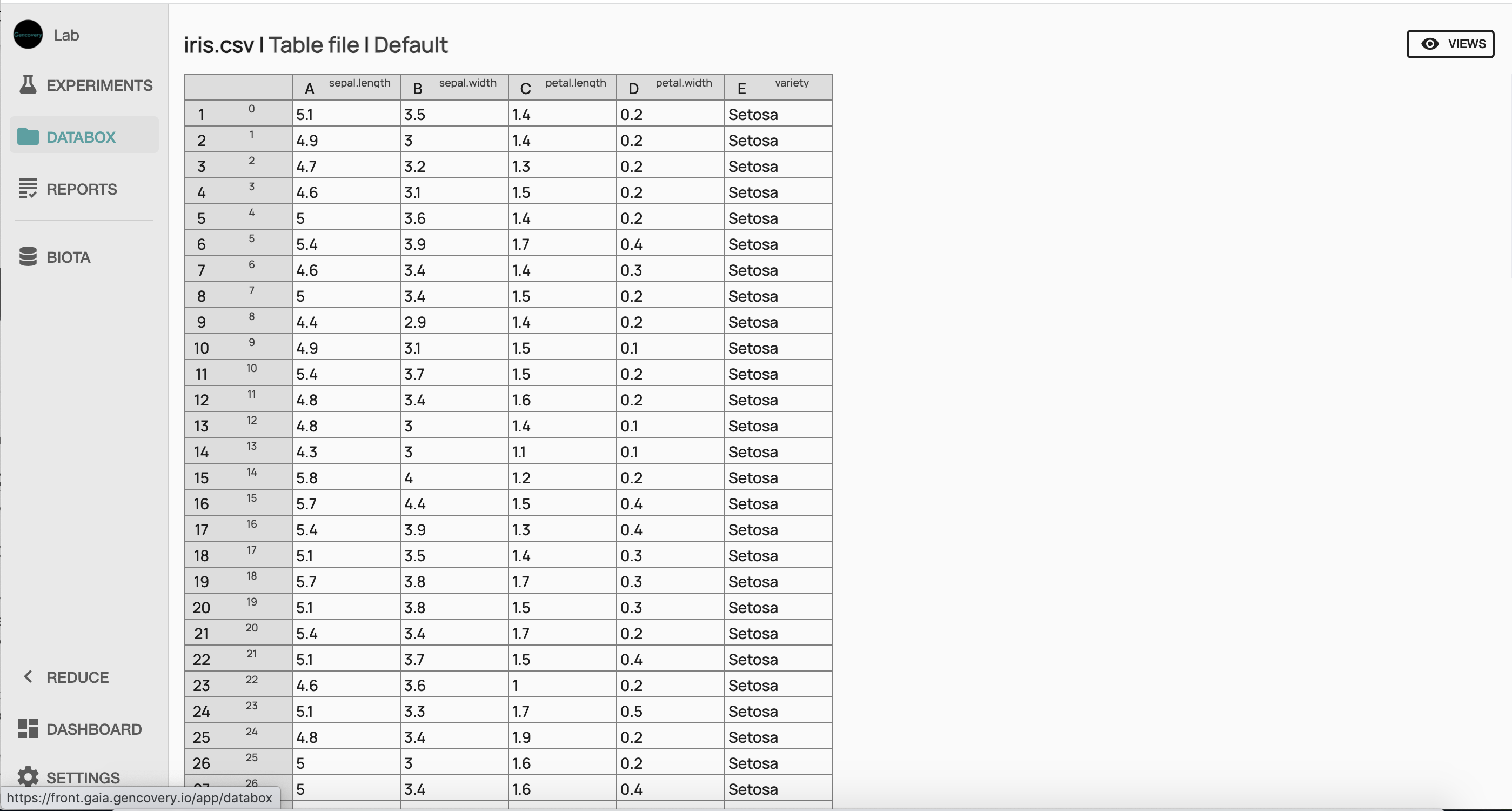
Here the first 4 columns correspond to each of the 4 features of the dataset (the sepal length, the sepal width, the petal length, the petal width, in centimeters), while each line corresponds to a sample of the dataset. The last column indicates the corresponding species (setosa, virginica or versicolor).
STEP 2 Building of the workflow for the clustering analysis
We start by creating a new experiment which will perform the K-Means clustering analysis of the Iris dataset. We then construct the workflow that will be used for our analysis, by selecting :
- the
K-Means process from our GAIA library , - the resource containing our processed data as input data, and
- the output process which will collect the result of our analysis.
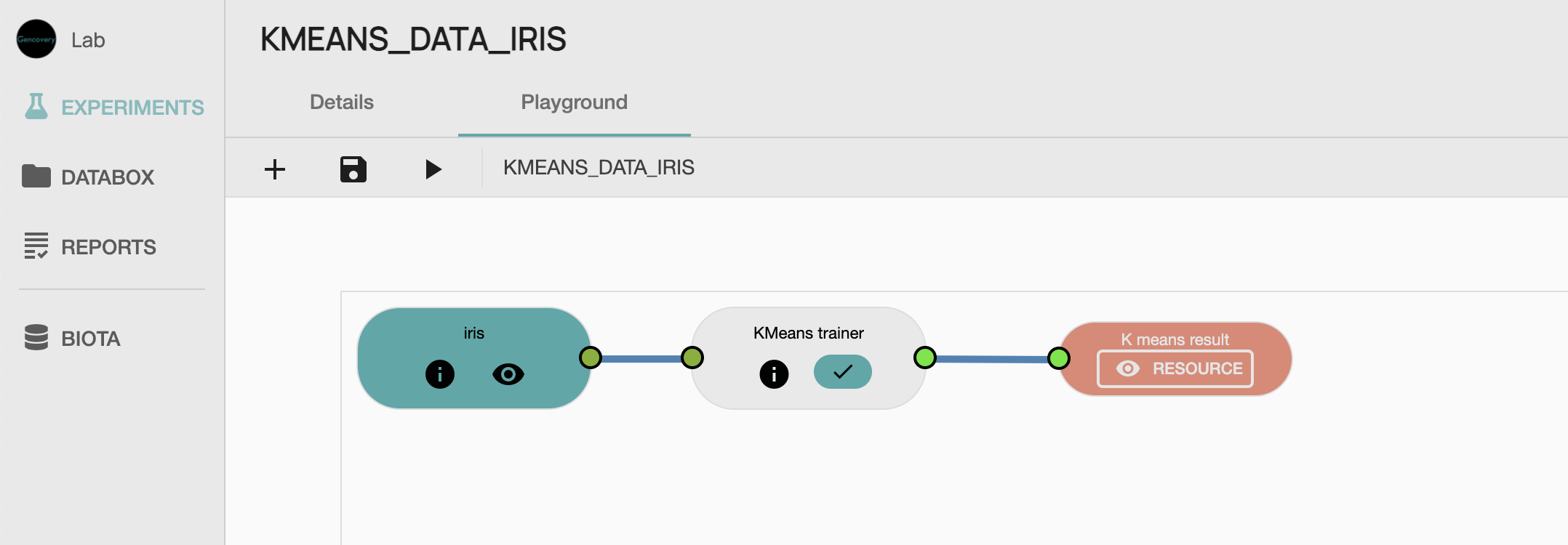
Some parameters of our processes then need to be specified:
- the parameter of the Kmeans trainer process determining the number of clusters we want to compute, set here to 3.
STEP 3 Running the clustering workflow analysis and viewing the results
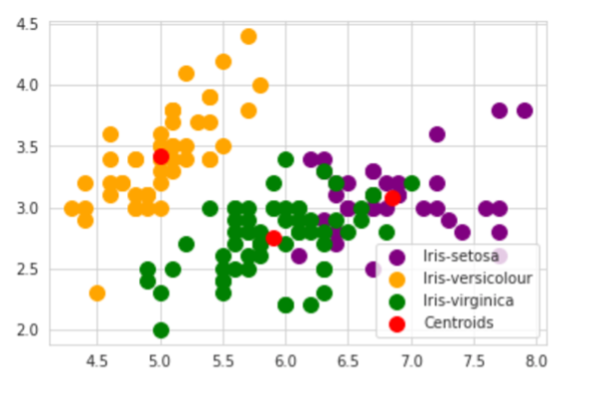
We can now run the experiment which will perform the K-Means clustering analysis of the Iris dataset, considering 3 clusters for our analysis. Once the experiment has been successfully run, we can view the result of the analysis in a tabular form, as well as in a 2D scatter plot.
In the tabular view, each line corresponds to a sample of the Iris dataset. The first 4 columns denote the features of each sample, whereas the last column corresponds to the cluster to which each sample has been associated. In the scatter plot view, each dot corresponds to a sample of the Iris dataset, while the color of the dot denotes the associated cluster.
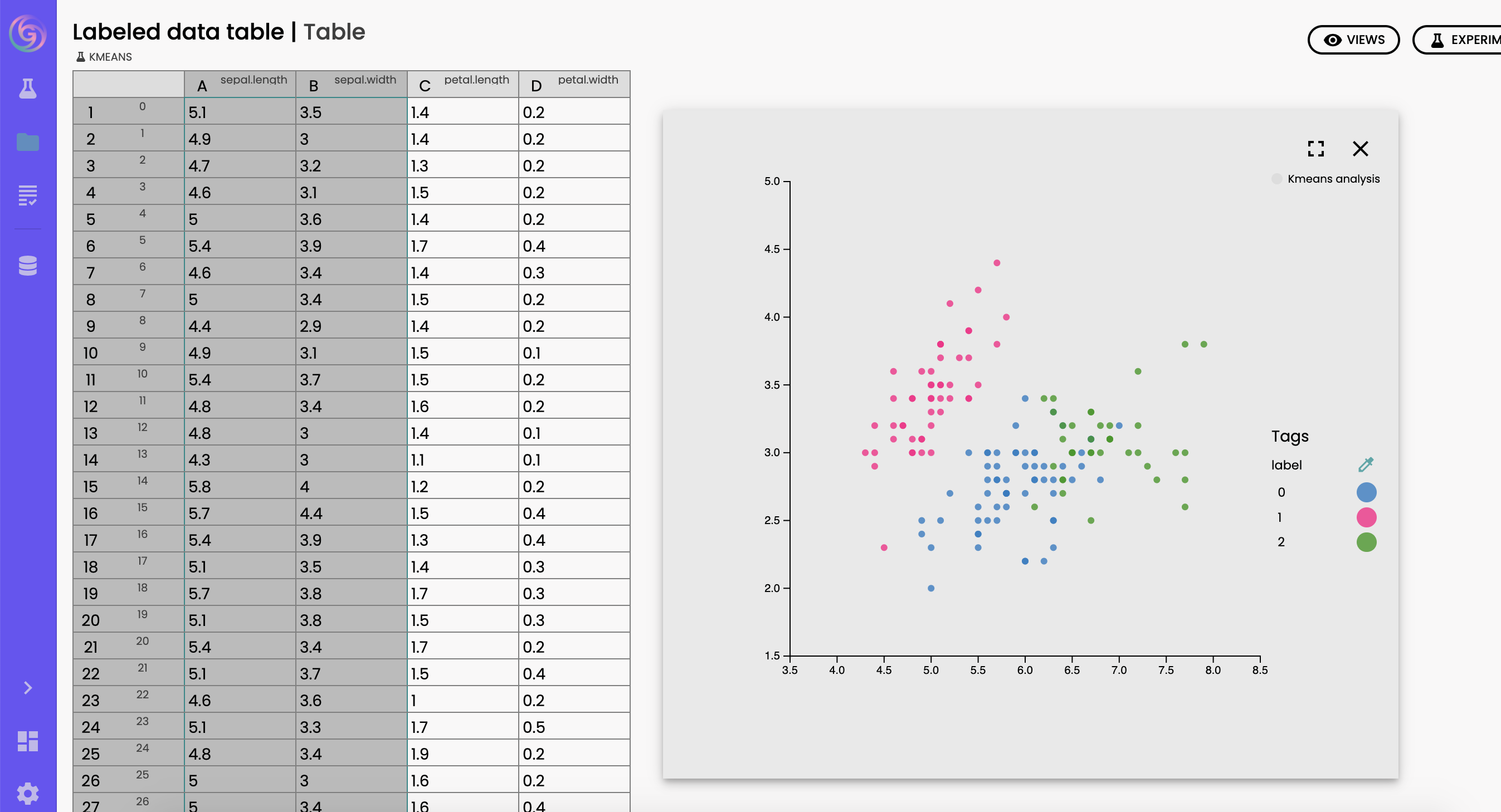
We can see that the obtained results are similar to the same type of analysis performed in the example treated in the following paper (https://www.researchgate.net/publication/336936265_Meta-Learning_to_Cluster, Figure 4).
Once validated, your experiment and your report can be shared among your collaborators.